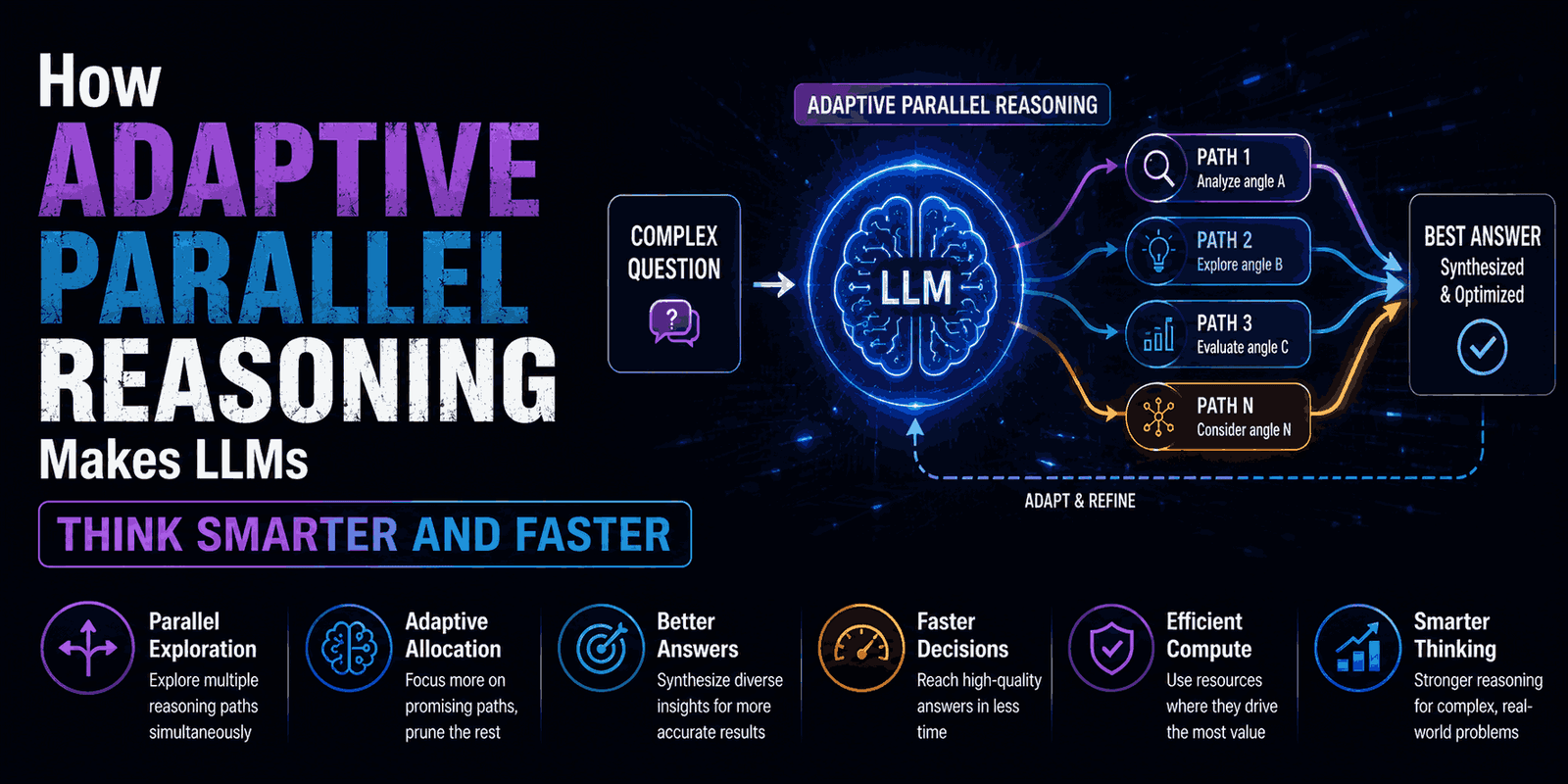
Imagine an AI model that doesn’t just process information but actively chooses how to think. What if it could recognize a tough problem, break it into smaller parts, work on those parts at the same time, and then bring all the solutions together? This isn’t just a cool idea; it’s the core of Adaptive Parallel Reasoning (APR). This new approach is a big step in making large language models (LLMs) much more efficient, faster, and ultimately, smarter.
Normally, LLMs tackle complex tasks one step at a time, much like a single person solving a puzzle. This works, but it can get really slow and clunky when problems become super intricate. APR changes this by letting LLMs “multitask” their thinking processes dynamically, meaning they decide when and how to do it.
Why Sequential LLM Thinking Can Be a Bottleneck
Modern LLMs have amazed us with their abilities to reason, write code, and act like intelligent assistants. This power often comes from generating lengthy “thought processes” – extra steps, explorations, and self-corrections – before giving a final answer. It’s how they explore options, fix mistakes, and build solid conclusions.
But this step-by-step thinking comes with some real drawbacks:
- Linear Scaling: The more steps an LLM needs, the longer it takes. For super complex tasks, users might wait minutes, even hours, for a response.
- Context Window Limits: Piling up too many intermediate thoughts can “clutter” the model’s working memory. This makes it harder for the LLM to focus on what’s important, a problem sometimes called “context-rot,” which can hurt performance.
- Compute Intensive: Longer sequences mean more tokens to process. This translates directly to higher computing power needs and more energy consumption.
To get around these limitations, researchers have increasingly looked into parallel reasoning. Instead of thinking one step after another, parallel reasoning lets models explore multiple solution paths or sub-problems at the same time, independently.
From Fixed Parallelism to LLMs Taking Control
While parallel reasoning clearly offers benefits, many early methods used fixed, predefined ways of working in parallel. The model didn’t get to choose when or how to parallelize; it was simply told to.
Let’s look at how parallel reasoning has evolved:
Simple Fork-and-Join Methods
These are straightforward. An LLM generates several complete reasoning paths in parallel and then combines them.
- Self-consistency/Majority Voting: Run the same problem multiple times, get a few answers, and pick the one that shows up most often.
- Best-of-N (BoN): Similar to self-consistency, but uses an additional AI “verifier” to choose the most promising solution from the independent attempts.
While easy to set up, these methods often waste computing power because the different reasoning paths might overlap or repeat work unnecessarily.
Heuristic-Based Structured Search
These methods try to break problems into distinct sub-tasks using known search strategies.
- Tree/Graph/Skeleton of Thoughts: These explore various “thoughts” in a structured way, like a decision tree. They then prune (cut off) less promising paths based on LLM evaluations.
- Monte-Carlo Tree Search (MCTS): This technique estimates how valuable different reasoning steps are by simulating future outcomes, balancing exploring new ideas with focusing on promising ones.
These approaches are better at splitting tasks into non-overlapping parts. However, they still need prior knowledge about how to best break down a problem, which isn’t always available or the best strategy for every situation.
Recent Fixed-Parallel Variants
Newer methods have refined fixed parallelism, but they still operate under a predetermined structure:
- ParaThinker: Trains a model to generate multiple reasoning threads in parallel, then combines them in two separate phases.
- GroupThink: Allows multiple parallel threads to see each other’s progress in real-time, letting them adapt as they generate.
- Hogwild! Inference: Enables parallel threads to share memory efficiently using techniques like KV cache sharing.
The Dawn of Adaptive Parallel Reasoning (APR)
The common thread in all these methods is that the decision to parallelize and the strategy used are given to the model, not by it. But what if the LLM could intelligently decide for itself when to work in parallel, how many paths to explore, and how to combine them, all based on the specific problem?
This is where Adaptive Parallel Reasoning (APR) steps in. APR lets the model dynamically decide whether to use sequential (step-by-step) or parallel operations during its thinking process. Essentially, an APR-capable model learns to control its own thought flow.
This shift offers major advantages:
- Learned Decomposition: Unlike methods like Tree-of-Thoughts, APR doesn’t need predefined rules for breaking down problems. Through training (especially reinforcement learning), the model learns general strategies, even discovering new ways to parallelize, like checking its own work simultaneously.
- Reduced Redundancy: Compared to simple Best-of-N approaches, APR models can control what each parallel thread does before it branches out. This leads to more unique, non-overlapping sub-tasks.
- Intelligent Parallelization: Crucially, APR models can choose not to parallelize when a problem is simple or when the effort of parallelization outweighs its benefits. This prevents wasting computing power on easy tasks.
In practice, APR is often implemented by having the model output special “tokens” that act as commands, telling the inference engine when to “think in parallel” and when to “think sequentially.”
How Adaptive Parallelism Gets Executed: Inference System Designs
Once an LLM decides to reason in parallel, how does the underlying system actually carry out these simultaneous thought processes? Most methods use a “fork-join” design, a concept borrowed from computer science:
- Fork: The main task is split into several sub-tasks or “threads.”
- Process Concurrently: These threads are then processed independently and at the same time by the inference engine.
- Join: The results from the parallel threads are gathered and combined into a final answer.
A key challenge during the “join” phase is managing the model’s internal memory (specifically, the KV cache). When independent threads generate tokens, they might start at similar “position IDs,” which can cause problems when trying to combine their KV caches. It’s like trying to merge multiple independent notebooks into one cohesive story where some pages have the same numbers but different content.
To handle this, two main approaches have emerged:
Modifying the Inference Engine: The Multiverse Approach
Some methods, like Multiverse, address KV cache aggregation by directly changing the LLM’s inference engine.
- Shared Prefix Optimization: They use techniques like RadixAttention to ensure that the common “prefix” (the initial prompt and sub-task list) is calculated only once, saving computation.
- KV Cache Stitching: During the join phase, these systems physically copy and “stitch” together the KV cache generated by each parallel thread. This avoids recomputing the cache, making it faster.
However, this approach comes with significant downsides:
- Engine Modification: It requires deep changes to the inference engine, which could lead to instability or errors if the referenced KV cache is unexpectedly removed.
- Distributional Shift: Stitching KV caches this way creates an unusual sequence view for the model. LLMs aren’t typically pre-trained on this, so it requires extensive extra training to align their behavior.
Engine-Agnostic Approach: ThreadWeaver
Other methods, such as ThreadWeaver, take a different path by keeping the core inference engine unchanged and managing the parallelization from the user’s side (client-side).
- Client-Side Orchestration: Instead of modifying the engine, the client gathers all text outputs from the independent branches.
- Re-Prefilling: For the “join” step, the client combines these text outputs into a single sequence and then sends it back to the engine for a second prefill. This generates a new, consistent KV cache for the final conclusion.
While this means some repeated computation (the second prefill), it’s generally less expensive than fully decoding everything again. The main advantages are:
- Ease of Adoption: No complex engine modifications mean easier integration with existing hardware and software.
- Standard Attention: The second prefill uses standard causal attention, making it easier to adapt existing sequential LLMs without a lot of re-training for new attention patterns.
- Flexibility: It supports hybrid models that can smoothly switch between sequential and parallel reasoning.
Teaching LLMs to Reason Adaptively in Parallel
An LLM won’t just wake up and decide to reason in parallel. It needs to be taught this complex behavior, especially how to output the special “control tokens” that tell the system how to parallelize.
The Role of Supervised Fine-Tuning (SFT)
Initially, models are often fine-tuned on examples where humans have shown how to use parallel reasoning steps. A key question here is whether SFT actually teaches the model a brand-new capability for parallel execution, or if it simply teaches the model the language to express its existing reasoning in a parallel format. This is still an active area of research.
The Challenge of Reward Design
Beyond just showing the model how to parallelize, we need to encourage it to do so effectively. Simply rewarding the model for starting more parallel threads can easily be “gamed,” leading to many short, useless threads.
Good reward design for APR focuses on two main goals:
- Efficiency via Critical Path: For parallel tasks, the total number of tokens generated isn’t the best measure of speed. Instead, researchers look at the “critical path” – the longest sequence of tokens that depend on each other. Minimizing this critical path length directly reduces the actual time it takes to get an answer.
- Correctness-Gated Efficiency: It’s crucial that the model only gets rewarded for efficient parallelization if it also produces a correct answer. This stops models from becoming super parallel but inaccurate. A common reward structure looks like this:
Reward = (Correctness) + (Correctness) × (Parallelization Metric). This means if the answer is wrong, there’s no reward for parallelization, no matter how efficient the parallel structure was.
Why Adaptive Parallel Reasoning Is a Game Changer
Adaptive Parallel Reasoning isn’t just a technical curiosity; it’s a huge step towards more capable and efficient AI. By allowing LLMs to intelligently manage their own reasoning processes, we can:
- Unlock Greater Problem-Solving Power: Tackle problems that are currently too complex or time-consuming for regular sequential LLMs.
- Boost Speed and Reduce Latency: Get answers faster, making user experiences better and enabling real-time AI applications.
- Enhance Computational Efficiency: Optimize how resources are used, leading to lower operating costs and a smaller environmental footprint for AI.
- Pave the Way for More Autonomous Agents: Create AI agents that can adapt their thinking strategies on the fly, leading to more robust and flexible behaviors.
This ability for an LLM to “think about its thinking” is a crucial step in AI’s evolution, bringing us closer to truly intelligent and adaptable systems.
Frequently Asked Questions about Adaptive Parallel Reasoning
What is Adaptive Parallel Reasoning (APR)?
APR is an advanced technique where a large language model (LLM) learns to dynamically decide when and how to break down complex problems into parallel sub-tasks and then coordinate their solutions. It allows LLMs to “multitask” their reasoning processes.
How does APR differ from traditional parallel reasoning?
Traditional parallel reasoning methods use a fixed, pre-determined structure for parallelization. In contrast, APR gives the LLM the autonomy to look at the problem and adaptively choose whether to reason step-by-step or in parallel, and how to structure that parallelism, based on the task’s specific needs.
What are the main benefits of APR for LLMs?
APR leads to faster response times, reduced computing costs, and improved accuracy for complex problems. It helps LLMs overcome context window limitations and avoid repeating computations by intelligently planning their reasoning paths.
Are there any challenges in implementing APR?
Yes, big challenges include designing robust inference systems that can efficiently handle parallel memory (like the KV cache), training models to consistently use the parallelization commands, and creating effective reward functions that encourage both correct answers and efficient parallel execution without being “gamed” by the model.
Final Thoughts
Adaptive Parallel Reasoning holds immense promise for the future of LLMs. By empowering AI models to intelligently manage their own reasoning flow, we’re not just making them faster, but fundamentally smarter. While there are still open questions around how stable training is, how to optimize for different hardware, and how to create even deeper parallel structures, the groundwork being laid today points to a future where LLMs handle complex challenges with incredible efficiency and adaptability. The journey toward truly autonomous and intelligent AI systems is a long one, but APR is undoubtedly a major stride forward.
Want to dive deeper into the cutting-edge of AI research and LLM advancements? Explore our other articles on advanced AI techniques and subscribe to our newsletter for the latest updates!